Smartsheet is a SaaS based application that assists users in managing projects, automating workflows, collaborating across teamms, mananaging resourcse and digital assets, and dashboarding and reporting for data sets. As a current employee of the comapany, I'm fairly biased in my opinions but do believe it to be a wonderful tool that is steps above your standard spreadsheet system. The tool offers a way to import datasets from CSV and XLSX directly from tools like Google Docs but also offers an API that allows you to create sheets on the fly.
There are often times when I'm researching or working on a new project where I retrieve log files or data files as CSV and dump them into an S3 for simple storage. Later I often retrieve the files and manually import them into a sheet to begin manipulating. It occurred to me that I could automate this process through the help of a Lambda and some basic code. This post provides a follow through of the original proof of concept I did in creating a solution for my own use at home.
Contents
Pre-requisites
This walkthrough assumes the following:
- You have a basic understanding of Python
- You have access to a Smarstheet Account
- You have setup and have access to your own AWS Account
- You have a basic understanding of Terraform
Creating the Infrastructure in Terraform
We begin our project by creating the basic infrastructure we will need to accomplish our task. We will create an S3 bucket to store our CSV files. Then we will craete the IAM roles we will need in order for our Lambda to function as we desire. We'll then store an API Secret that our code can use to interact with the Smartsheet API and, finally, we'll build the lambda that will run our code. If you get lost at any point, the full code can be found on my in the following repository: gstotts/s3-to-smartsheet-example
Building the S3
We start our project by creating a main.tf file that we will utilize to setup our Terraform backends. I typically use Terraform Cloud to manage my state and deploy but you can store your state files locally if desired. You'll at least need the following for your configuration to declare the required AWS provider:
terraform {
required_version = ">= 1.0.0"
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.25.0"
}
}
}
provider "aws" {
region = "us-east-2"
}Note: Be sure to replace the region above with your desired AWS region.
Next we'll create a locals.tf file that will contain some local variables we'll use throughout the build. For now, we'll add one that helps us get the account ID of our AWS account
data "aws_caller_identity" "current" {}
locals {
account_id = data.aws_caller_identity.current.account_id
}I also created a variables.tf file to use for any variables we might desire to add to our code. We will start it by adding a basic variable to handle tagging all associated resources with any desired default tags.
variable "tag_all" {
description = "Tags to apply by default to all resources"
type = map(any)
default = {
"project" = "s3_to_smartsheet",
"tf_managed" = "true"
}
}Now we can create our S3 bucket that will be used to dump our data files in and trigger the lambda. We create this in an s3.tf file for clarity.
resource "aws_s3_bucket" "reporting_bucket" {
bucket = "reporting-${local.account_id}"
tags = merge({ "Name" : "reporting-${local.account_id}" }, var.tag_all)
}
resource "aws_s3_bucket_server_side_encryption_configuration" "default" {
bucket = aws_s3_bucket.reporting_bucket.id
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256"
}
}
}We will also define that we do not want the s3 bucket to be public as well as setup versioning of objects within the bucket and a lifecycle rule to remove non-current versions aafter 3 days.
resource "aws_s3_bucket_public_access_block" "reporting_block_public_access" {
bucket = aws_s3_bucket.reporting_bucket.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
resource "aws_s3_bucket_versioning" "reporting_versioning" {
bucket = aws_s3_bucket.reporting_bucket.id
versioning_configuration {
status = "Enabled"
}
}
resource "aws_s3_bucket_lifecycle_configuration" "reporting_lifecycle" {
bucket = aws_s3_bucket.reporting_bucket.id
rule {
id = "remove-noncurrent"
filter {}
status = "Enabled"
noncurrent_version_expiration {
newer_noncurrent_versions = 14
noncurrent_days = 3
}
}
}IAM Roles
Our bucket is set but our Lambda is going to need to have a role that it can assume in order to accomplish pulling the object from S3 to Smartsheet. Let's create that in a file named iam.tf. First we create our role and give the AWS Lambda service the ability to assume the role.
resource "aws_iam_role" "reporting_lambda_role" {
name = "reporting-lambda-role"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Action = [
"sts:AssumeRole"
]
Effect = "Allow",
Principal = {
Service = [
"lambda.amazonaws.com"
]
}
}
]
})
tags = merge({ "Name" : "reporting-lambda-role" }, var.tag_all)
}Now we create a policy that allows the lambda to write logs as well as get objects from the S3 bucket we've created.
resource "aws_iam_policy" "reporting_lambda_iam_policy" {
name = "reporting-lambda-policy"
path = "/"
description = "Policy for the reporting lambda"
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = [
"logs:PutLogEvents",
"logs:CreateLogGroup",
"logs:CreateLogStream"
]
Effect = "Allow",
Resource = "arn:aws:logs:*:*:*"
},
{
Action = [
"s3:GetObject"
]
Effect = "Allow",
Resource = "${aws_s3_bucket.reporting_bucket.arn}/*"
}
]
})
}
resource "aws_iam_role_policy_attachment" "reporting_lambda_role_attach" {
role = aws_iam_role.reporting_lambda_role.name
policy_arn = aws_iam_policy.reporting_lambda_iam_policy.arn
}Storing a Secret
In order to interact with the Smartsheet API, we need to use an API token. We'll want to store that securely and not in our code. Using Secrets Manager is the perfect tool for this. We will manually login to our AWS console to store this item and then will add the code to retrieve it when it is needed.
First, let's login to Smartsheet and create a token.
-
Login to app.smartsheet.com with your account.
-
Click on the
Accountbutton on the sidebar (located at the lower left of your screen).

- Open your
Personal Settings.
- Click
API Tokenand then click theGenerate new access tokenbutton.

- Give your token a name and click
Ok.

- Copy the generated token for now.
Now we need to add the secret we were given to AWS Secrets Manager.
-
Login to your AWS Account and navigate to the
Secrets Manager > Secrets. -
Click
Store a new secreton the right hand side. -
Select
Other type of secretfor Secret type and then add a key/value pair of 'token' and the secret value you were given. ClickNextwhen finished.
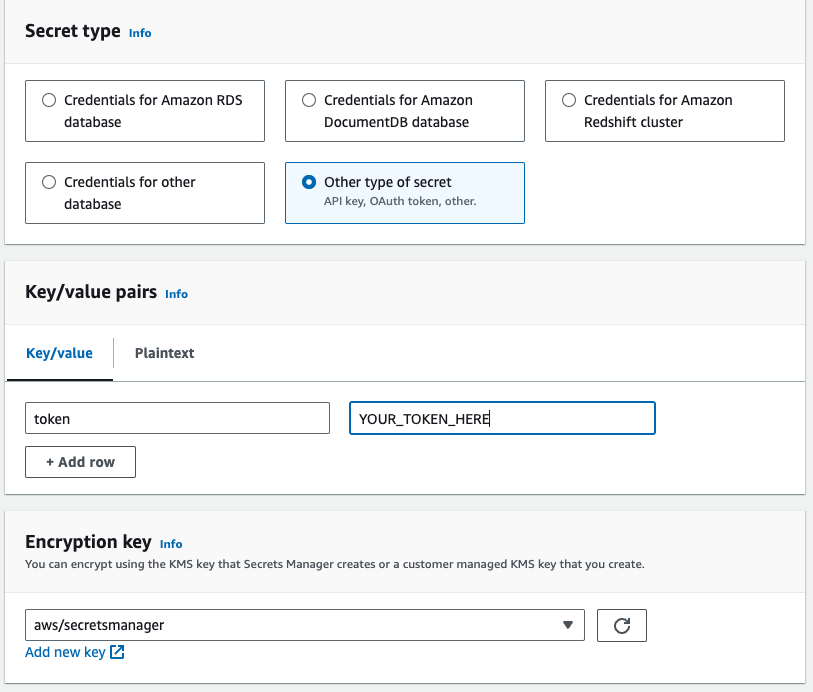
-
Give your secret a name of
smar_tokenand clickNext. -
Skip setting up rotation and move to review and click
Store.
Now that our secret lives in AWS, let's add the code to retrieve it. Return to your locals.tf file and add the following to get the secret and retrieve its value for our script:
data "aws_secretsmanager_secret" "smar_token" {
name = "smar_token"
}
data "aws_secretsmanager_secret_version" "smar_access_token" {
secret_id = data.aws_secretsmanager_secret.smar_token.id
}Building the Lambda
The last piece of our infrastructure build involves creating the lambda that will run our code and tying it to the S3 bucket actions. We create a file named lambda.tf and begin by adding the file drop lambda details. Note, we have not yet create the script but we'll define a location where it will exist and where we'll keep a zip to upload.
Here is our basic lambda function. You'll note that we are going to store the code for the lambda in /functions/report_to_smartsheet/ folder within our current working directory. We also set the environment variable that the Smartsheet SDK will need in order to retrieve our token.
resource "aws_lambda_function" "file_drop_lambda" {
function_name = "reporting-lambda"
filename = "${path.module}/functions/report_to_smartsheet/ReportToSmartsheet.zip"
role = aws_iam_role.reporting_lambda_role.arn
handler = "ReportToSmartsheet.lambda_handler"
runtime = "python3.11"
architectures = ["arm64"]
source_code_hash = filebase64sha256("${path.module}/functions/report_to_smartsheet/ReportToSmartsheet.zip")
layers = [aws_lambda_layer_version.smartsheet_lambda_layer.arn]
environment {
variables = {
SMARTSHEET_ACCESS_TOKEN = jsondecode(data.aws_secretsmanager_secret_version.smar_access_token.secret_string)["token"]
}
}
tags = merge({ "Name" : "reporting-lambda" }, var.tag_all)
}We also need to define the permissions for our lambda along with a layer that will house the Smartsheet SDK. We also set the maximum retry on our invoke event to 0 for now to avoid unnecessarily duplication of files in Smartsheet if a run fails.
resource "aws_lambda_permission" "allow_s3_invoke_lambda" {
statement_id = "AllowS3Invoke"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.file_drop_lambda.function_name
principal = "s3.amazonaws.com"
source_arn = aws_s3_bucket.reporting_bucket.arn
}
resource "aws_lambda_layer_version" "smartsheet_lambda_layer" {
filename = "${path.module}/functions/report_to_smartsheet/smartsheet.zip"
layer_name = "smartsheet_sdk"
compatible_architectures = ["arm64"]
compatible_runtimes = ["python3.11"]
}
resource "aws_lambda_function_event_invoke_config" "error_handle" {
function_name = aws_lambda_function.file_drop_lambda.function_name
maximum_event_age_in_seconds = 60
maximum_retry_attempts = 0
}Lastly, we need to tie the S3 to the Lambda. We go back to our s3.tf and add the following:
resource "aws_s3_bucket_notification" "reporting_bucket_notification" {
bucket = aws_s3_bucket.reporting_bucket.id
lambda_function {
lambda_function_arn = aws_lambda_function.file_drop_lambda.arn
events = ["s3:ObjectCreated:*"]
}
depends_on = [aws_lambda_permission.allow_s3_invoke_lambda]
}Coding the Lambda
Report to Smartsheet Code Walkthrough
As mentioned before, we'll write our code in a folder within our current project named /function/report_to_smartsheet. Within that folder, we start by creating our file ReportToSmartsheet.py and begin by defining the few items we'll need to import for use.
#!/bin/python3
import boto3
import urllib.parse
import logging
import smartsheetNext we define a few global variables we'll use - the folder ID for where we want files to be placed (You can find this in the properties of a created folder in your Smartsheet) and the region we defind for our infrastructure earlier.
FOLDER_ID = "678637063169924"
region = "us-east-2"Using AWS boto3, we create a basic client for S3 and setup initial logging.
s3 = boto3.client('s3', region_name=region)
logger = logging.getLogger()
logger.setLevel(logging.INFO)Every Lambda utilizes a handler to taken in event and context data. We define that as a function named lambda_handler. We'll create two more functions: one to get the file from s3 and return the data and the name we'll use for the sheet and another to create the actual sheet using the data and given name.
def lambda_handler(event, context):
logger.info(f'[+] Lambda Invocation Starting')
data, sheet_name = get_file_from_s3(event)
create_sheet(data, sheet_name)
return {
'statusCode': 200,
'body': '[+] Lambda Invocation Complete'
}In the get_file_from_s3 function, we use the event to get the bucket name and the object key.
def get_file_from_s3(event):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'])
Next we try to retrieve the object placed in the bucket and return an error if we cannot.
try:
logger.info(f'[+] Retrieving Object {key} from {bucket}')
response = s3.get_object(Bucket=bucket, Key=key)
if response['ResponseMetadata']['HTTPStatusCode'] != 200:
logger.error(f'[-] Error: Invalid Status Code Retrieving Object {key} from {bucket}')
return {
'statusCode': response['ResponseMetadata']['HTTPStatusCode'],
'error': 'Invalid Status Code Retrieving Object' + key + ' from '+ bucket
}
except Exception as e:
logger.error(f'[-] Error Retreiving Object {key} from {bucket}')
logger.error(e)
raise e
logger.info(f'[+] Successfully Retrieved {key} from {bucket}')Then we attempt to get the data from the object file and return the data and filename (to use as the sheet name when we create).
try:
data = response['Body'].read().decode('utf-8')
except Exception as e:
logger.error(f'[-] Error Reading and Decoding File {key}')
logger.error(e)
raise e
logger.info(f'[+] Successfully read data from {key}')
return data, key.split('.')[0]There were a couple of different options for creating this sheet. One would involve saving a temporary file and uploading it as an import to Smartsheet. I wanted to avoid having an file operations so instead I opted to have the sheet created all in code without. First I created a sheet object that we'll add our details to.
def create_sheet(data, sheet_name):
sheet = smartsheet.models.sheet.Sheet()
sheet.name = sheet_nameNext we iterate over the first line of data we're given in order to identify the column headings we need for the sheet. To make things simple, we'll assign each column the type of TEXT_NUMBER and set whatever the first column is as Primary. If I knew more about the data I'd want to upload each time, I could define this much more but I wanted the Lambda to be flexible.
count = 0
for column_name in (data.splitlines()[0]).split(','):
col = smartsheet.models.column.Column()
if count == 0:
col.primary = True
else:
col.primary = False
col.title = column_name
col.type = smartsheet.models.enums.column_type.ColumnType.TEXT_NUMBER
sheet.columns.append(col)
count += 1Next we try to create the sheet in Smartsheet. We do this prior to adding the row data as we need the column ids prior to doing so.
try:
smart = smartsheet.Smartsheet()
smart.errors_as_exceptions(True)
except ValueError as e:
logger.error(f'[-] Error: SMARTSHEET_ACCESS_TOKEN must be set')
raise e
logger.info(f'[+] Creating Sheet: {sheet.name}')
result = smart.Folders.create_sheet_in_folder(
FOLDER_ID,
sheet
)Finally, we interate over the remaining data which contains our actual rows. For each row we create cell objects assigned to the columns in the order they go through. We use the split() option in order to determine the contents of each cell.
rows = []
for row in data.splitlines()[1:]:
new_row = smartsheet.models.row.Row()
new_row.to_top = True
column = 0
for data in row.split(','):
cell = smartsheet.models.cell.Cell()
cell.column_id = result.data.columns[column].id
cell.value = data
new_row.cells.append(cell)
column += 1
rows.append(new_row)
sheet = smart.Sheets.get_sheet(result.data.id)
sheet.add_rows(rows)
return sheetPreparing the Code for Lambda
Now that we have our code, we need to package it for use in our Lambda. We'll do this by creating a Makefile that will zip our code as well as the required Smartsheet SDK. The terraform we defined earlier set the names for us as ReportToSmartsheet.zip and smartsheet.zip and have them resulting in our /functions/report_to_smartsheet/ folder.
In the root of our project, we create a file named Makefile. We start by creating the command zip. You'll note the line .PHONY first -- this tells make to ignore any filenames of the same name zip.
.PHONY: zip
zip:
echo "Hello!"If we run this now using make zip, all we'll see is 'Hello!' printed to our terminal. Let's replace that with the basic functionality we'll need.
We start by changing directories to where our code exits and zipping our ReportToSmartsheet.py file.
.PHONY: zip
zip:
cd functions/report_to_smartsheet/ && zip ReportToSmartsheet.zip ReportToSmartsheet.pyNext, we want to create our virtual environment and create a zip of the Smartsheet SDK to upload with our code as a layer.
.PHONY: zip
zip:
cd functions/report_to_smartsheet/ && zip ReportToSmartsheet.zip ReportToSmartsheet.py
cd packages && python3 -m venv venv && source venv/bin/activate && mkdir python && cd python && \
pip3 install smartsheet-python-sdk -t . && \
cd .. && zip -r smartsheet.zip python && mv smartsheet.zip ../functions/report_to_smartsheet/smartsheet.zip && \
cd .. && rm -rf packages Runnning make zip will now create the files we need in the appropriate locations. We can
Deploying
We've finished all of our coding and can deploy by running our basic terraform commands:
terraform init
terraform plan
terraform apply